Accelerate Analytics with Greenplum Data-Warehouse & dbt

A hands-on tutorial to help you build & deploy your first dbt project on the Greenplum data warehouse.
dbt or data-build-tool is a transformation tool in the ELT pipeline that lets teams transform data, following software engineering best practices. Through native support for connectivity to many data warehouses, dbt runs SQL queries against a database warehouse platform or query engine to materialise data as tables and views.
It is used to modularise and centralise your data-warehouse analytics code, enabling teams to collaborate on data models, version them, and test and document queries before safely deploying them to production, with monitoring and visibility.
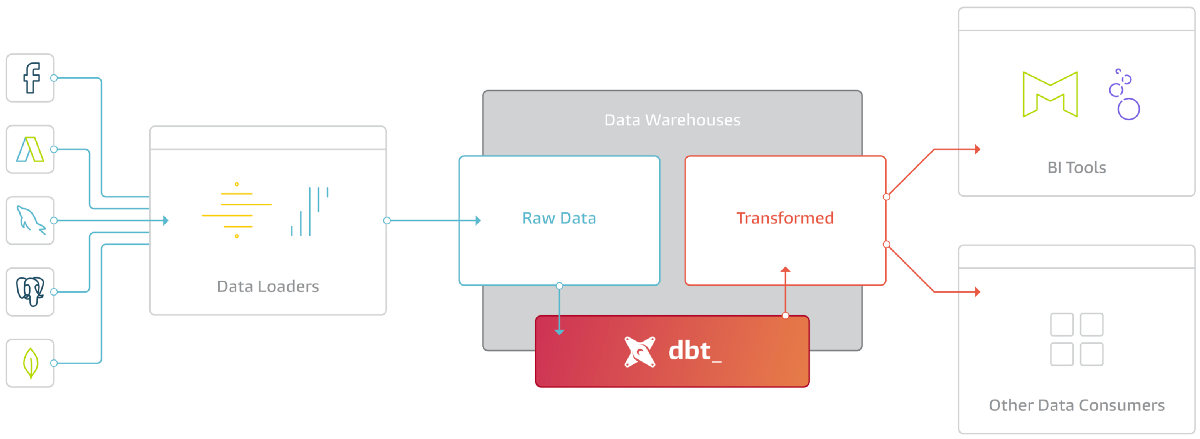
In this blog post, we will see how **Greenplum **and dbt can operate together to handle reliable and high-performance Big Data workloads and data transformations with simplicity and elasticity thanks to the dbt-greenplum adapter built by the Greenplum community.
What is Greenplum Data Warehouse?
Greenplum is an advanced, fully featured, open-source MPP data warehouse based on PostgreSQL. It provides powerful and rapid analytics on petabyte-scale data volumes. Uniquely geared toward big data analytics.
Greenplum is powered by the world's most advanced cost-based query optimiser delivering high analytical query performance on large data volumes.
For more details, take a look at VMware Greenplum docs
Key Features of Greenplum
- Cloud-agnostic for flexible deployment in the public cloud, private cloud, or on-premise
- Analytics from business intelligence to artificial intelligence
- Handle streaming data and enterprise ETL with ease
- Maximise uptime and protect data integrity
- Industry-leading performance
- Scales to petabytes of data
- Based on open-source projects like PostgreSQL offers an open ecosystem and integration with popular tools.
- Massively parallel, highly concurrent architecture
- Comes with libraries for advanced analytics to process geospatial, text, machine learning, graph, time series, and artificial intelligence
- Parallel, high throughput data access and federated query processing across heterogeneous data sources from object storage like AWS S3, GCS, and Azure Blob Storage to external databases like PostgreSQL, SQL Server, and Oracle
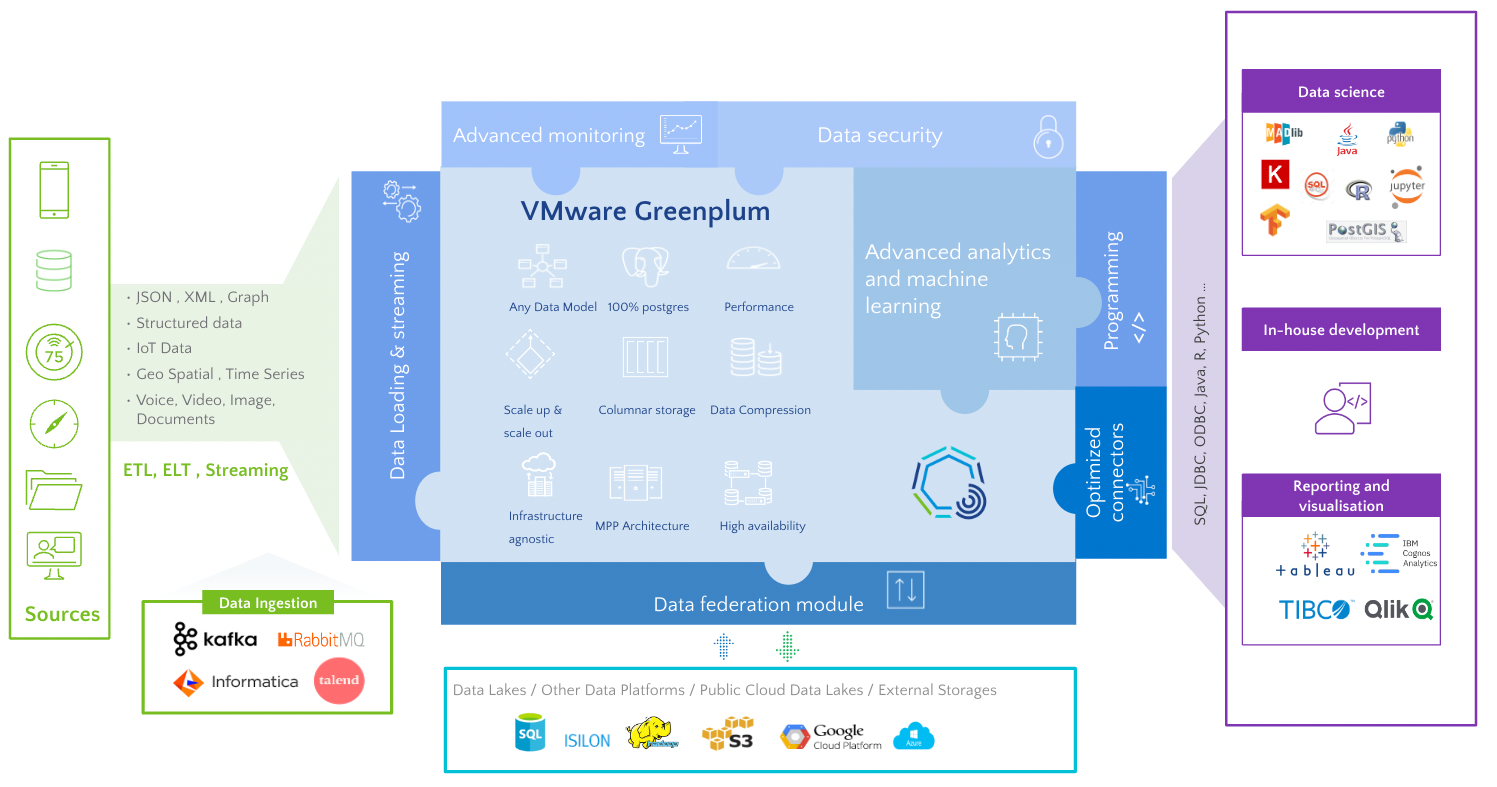
dbt + Greenplum integration:
Using Greenplum and dbt together enables organisations to focus on data without worrying about performance tuning, resource allocation, testing, change management, documentation…
Since Greenplum is a PostgreSQL-based data warehouse, customers can use the dbt-postgres adapter developed and maintained by dbt Labs. Yet, users can now use the dbt-greenplum adapter: https://docs.getdbt.com/reference/warehouse-setups/greenplum-setup.
It unlocks the benefits of a mighty data warehouse. It is easy to set up, connecting to Greenplum has never been simpler, and it provides better defaults.
Getting started:
Step 1: Setup environment
Installing dbt-greenplum:
- First, we must create a new Python environment and then install dbt-greenplum using pip3; it is the easiest way to install the adapter.
Installing dbt-greenplum will also install dbt-core and any other dependencies.
$ python3 -m venv dbt-env
$ source dbt-env/bin/activate
$ pip install dbt-greenplum
2. You can now check if everything works by running the dbt — version.
$ dbt --version
Core:
- installed: 1.2.0
- latest: 1.4.1 - Update available!
Your version of dbt-core is out of date!
You can find instructions for upgrading here:
https://docs.getdbt.com/docs/installation
Plugins:
- postgres: 1.2.0 - Update available!
- greenplum: 1.2.0 - Up to date!
At least one plugin is out of date or incompatible with dbt-core.
You can find instructions for upgrading here:
https://docs.getdbt.com/docs/installation
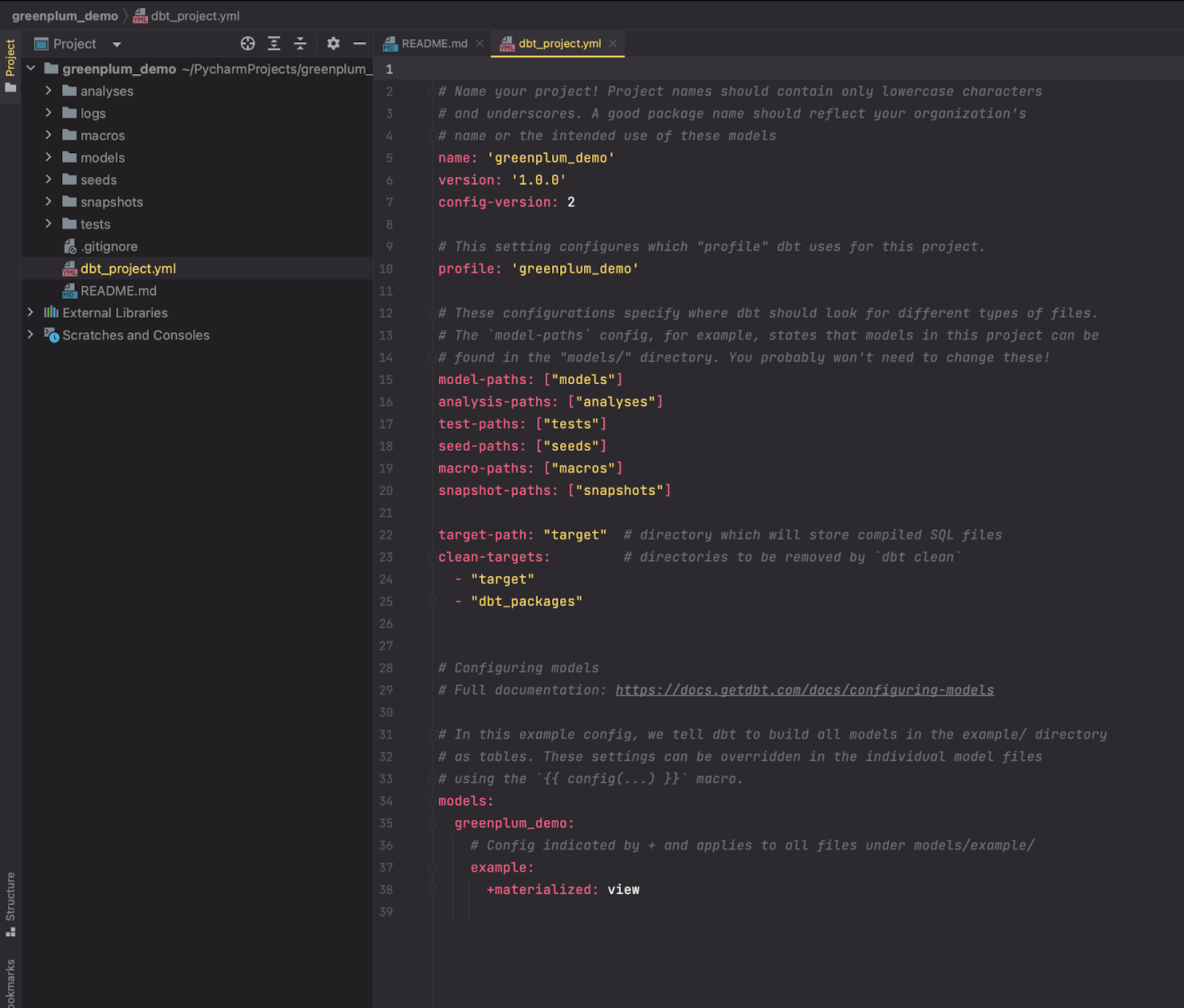
3. Initiate the greenplum_demo project using the init command, then move into it:
$ dbt init greenplum_demo
$ cd greenplum_demo
You can now see the dbt's project structured like this:
Connect to Greenplum Configuration:
In this step, we configure the connection between dbt and Greenplum using a profile and a YAML file with all the connection details to the Greenplum data warehouse.
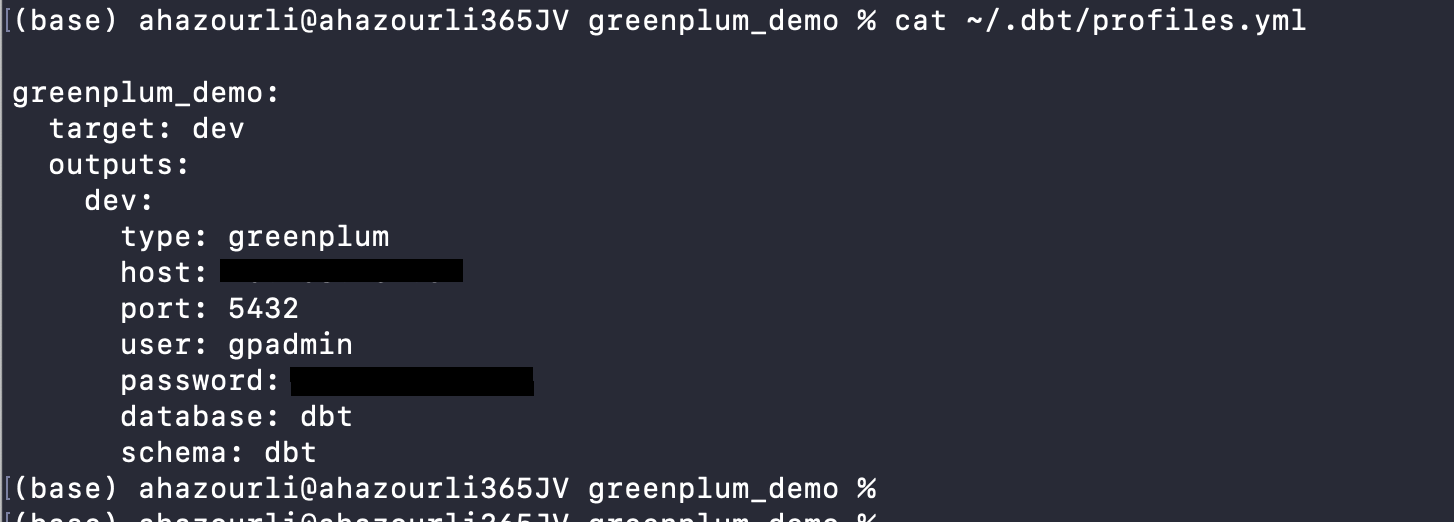
- Create a file in the ~/.dbt/ directory named profiles.yml.
$ vi ~/.dbt/profile.yml - Copy the following and paste it into the new profiles.yml file. Make sure you update the values where noted.
greenplum_demo: target: dev outputs: dev: type: greenplum host: hostname user: username password: password port: port database: database name schema: dbt schema
Here's the profile file used for this blog:
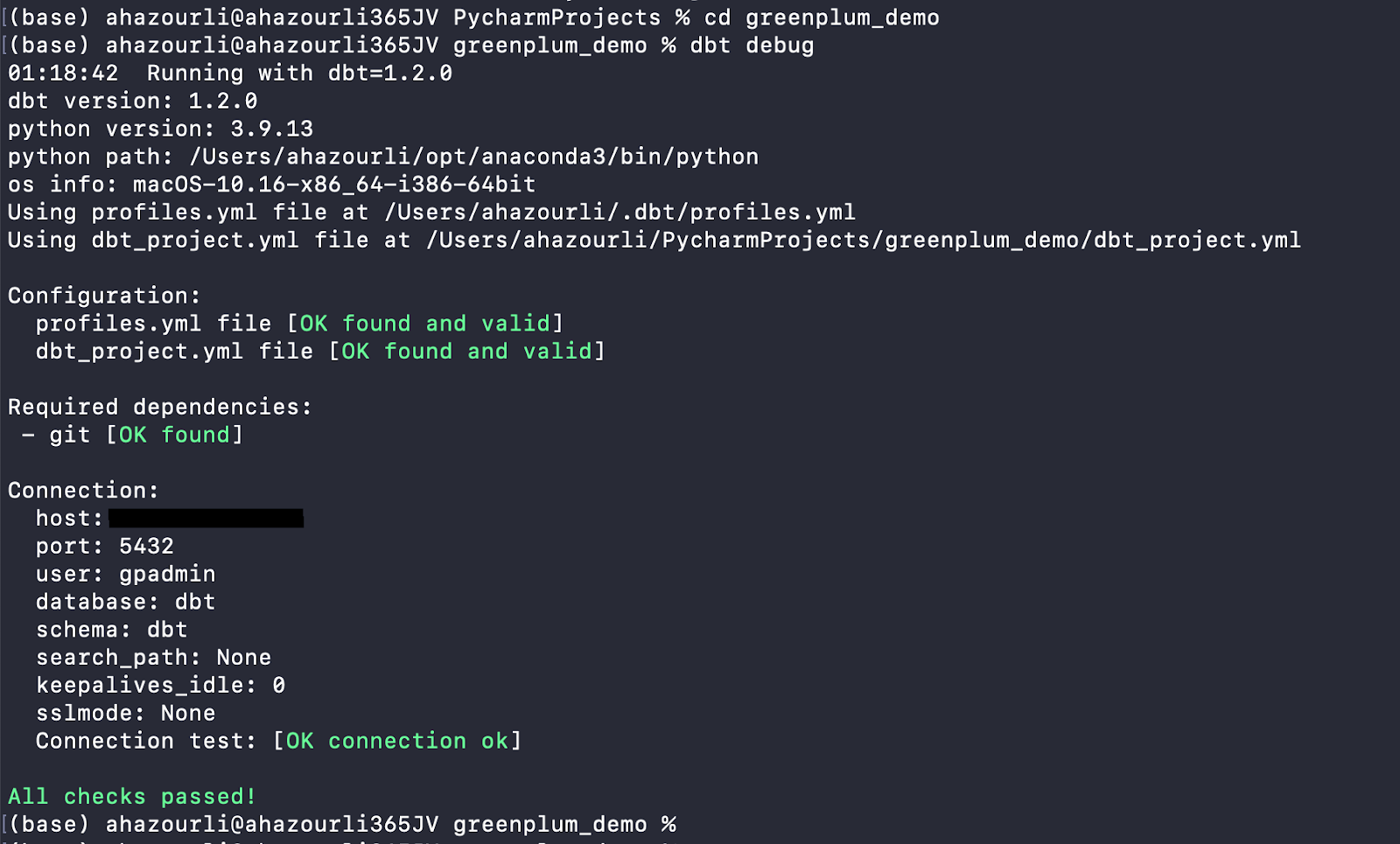
- Run the debug command from your project to confirm that you can successfully connect:
$ dbt debug
Step 2: Perform your first dbt run
dbt project has some example models in it. We will check that we can run them to confirm everything is in order.
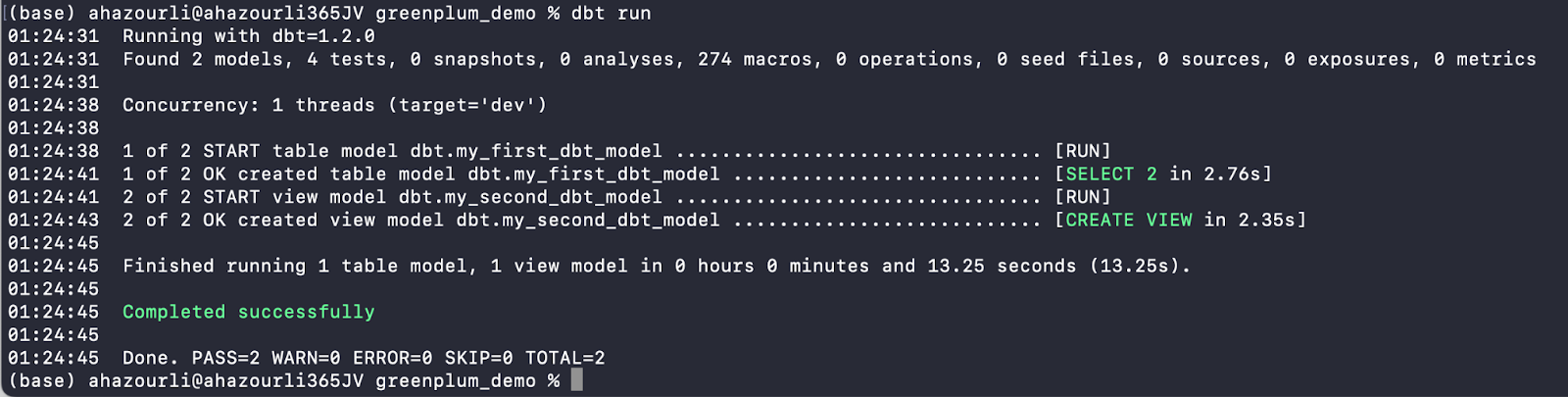
- Enter the run command to build example models:
$ dbt run
It would be best if you had an output that looks like this:
Step 3: Build your first dbt-greenplum models:
The **dbt-greenplum **adapter guides users to an improved experience with less effort to achieve better performance. Users can materialise their tables in the best possible way to optimise their performance by simply choosing the suitable storage model (column or row-oriented, append-optimised tables), distribution, partitioning and data compression strategy.
It's now time to build a dbt-greenplum model with advanced configurations!
- Open your project in your favourite code editor and create our first dbt models.
- Create two SQL files, classic_dbt_model.sql and greenplum_dbt_model.sql, in the models' directory to see the benefits of having a dbt-greenplum adapter.
For this blog, we use Greenplum generate_series and random functions to create a large six months CPU Usage table for 1000 devices with 1-minute intervals, ending now, which generates 265 million rows!
SELECT time, device_id, random()*100 as cpu_usage
FROM generate_series(
now() - INTERVAL '6 months',
now(),
INTERVAL '1 minute'
) as time,
generate_series(1,1000) device_id;
- Create the first file named models/classic_dbt_model.sql, and paste the following:
{{ config(materialized='table') }}
with source_data as (
SELECT time, device_id, random()*100 as cpu_usage
FROM generate_series(
now() - INTERVAL '6 months',
now(),
INTERVAL '1 minute'
) as time,
generate_series(1,1000) device_id
)
select *
from source_data
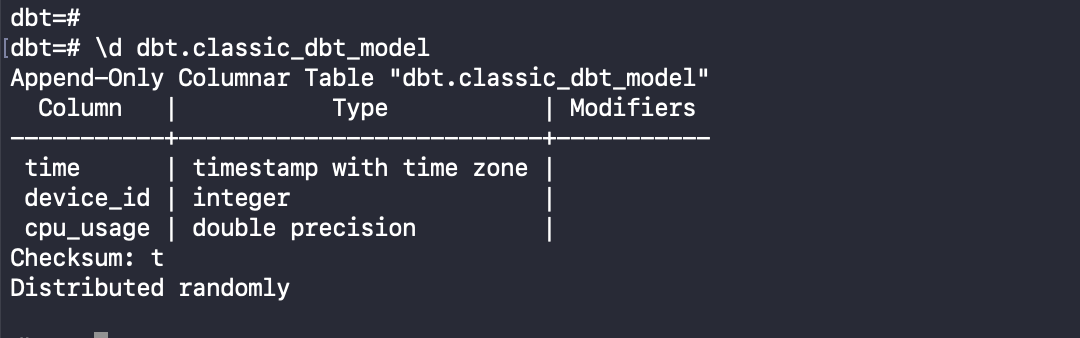
This model will create a randomly distributed Greenplum table without advanced or powerful features.
- On the other hand, create the second file named models/greenplum_dbt_model.sql, and paste the following code:
{% set fields_string %}
time timestamp NULL,
device_id int null,
cpu_usage double precision
{% endset %}
{% set raw_partition %}
PARTITION BY RANGE (time)
(
START ('2022-06-01'::timestamp) INCLUSIVE
END ('2024-01-01'::timestamp) EXCLUSIVE
EVERY (INTERVAL '1 day'),
DEFAULT PARTITION extra
);
{% endset %}
{{
config(
materialized='table',
distributed_by='device_id',
appendonly='true',
orientation='column',
compresstype='ZLIB',
compresslevel=3,
fields_string=fields_string,
raw_partition=raw_partition,
default_partition_name='other_data'
)
}}
with source_data as (
SELECT time, device_id, random()*100 as cpu_usage
FROM generate_series(
now() - INTERVAL '6 months',
now(),
INTERVAL '1 minute'
) as time,
generate_series(1,1000) device_id
)
select *
from source_data
This model will create a Greenplum column-oriented, append-optimised table distributed across segments by the device_id column key. It is partitioned on the time column with a daily interval, making it easier to manage and query data. Also, it uses the ZLIB algorithm with a compressed level = 3.
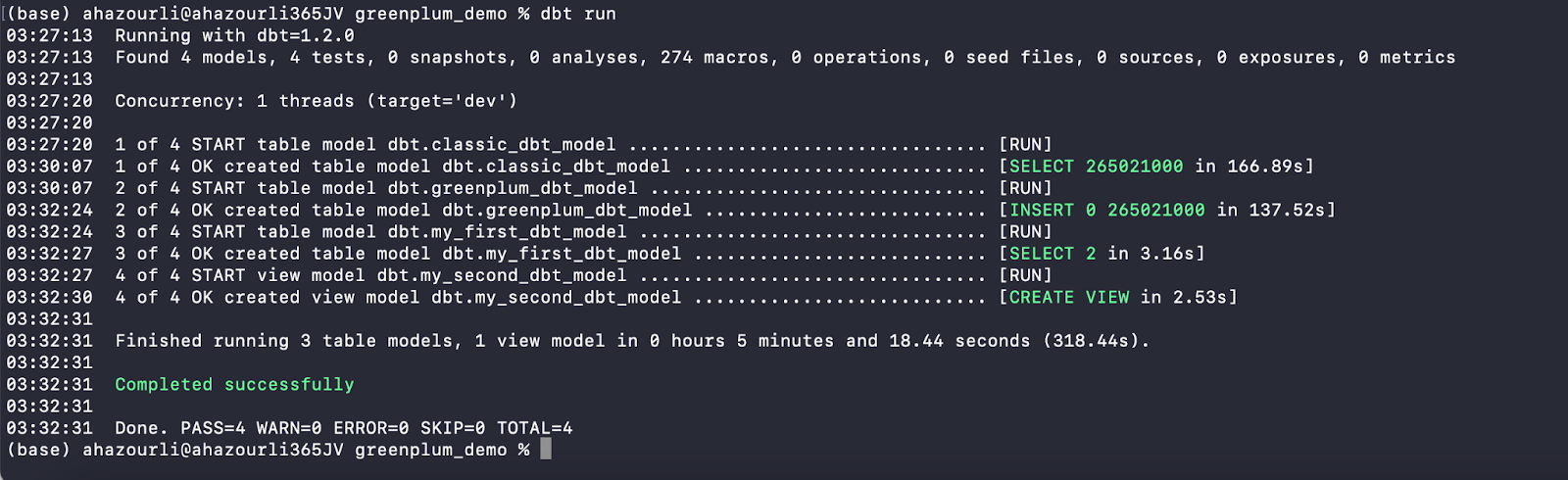
- Let's now run dbt models using:
$ dbt run
- To see the generated SQL by dbt, which ran on Greenplum, go to */target/run *directory:
- classic_dbt_model.sql:
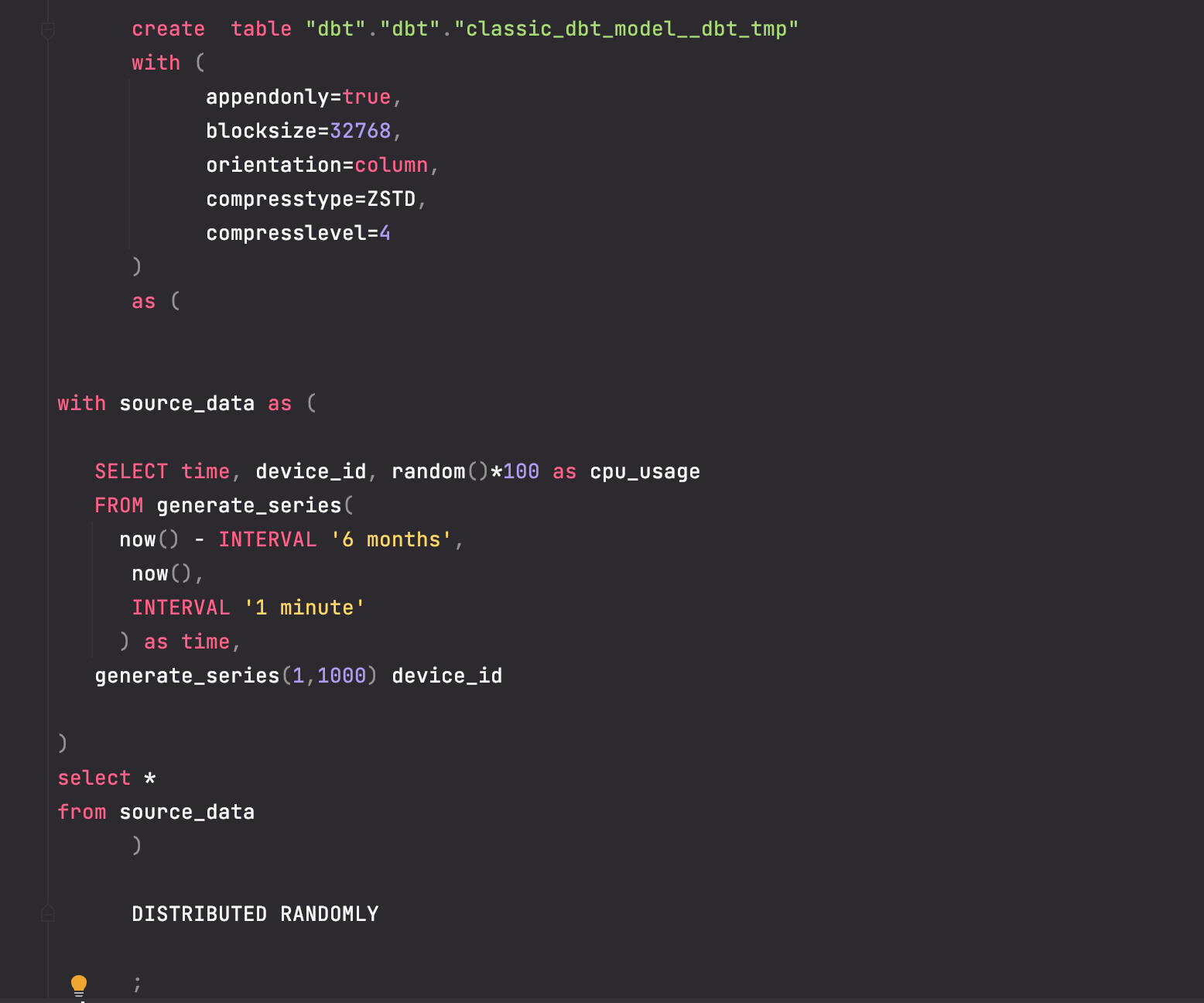
This model created a 265 million rows table randomly distributed with default Greenplum options.
- greenplum_dbt_model.sql:
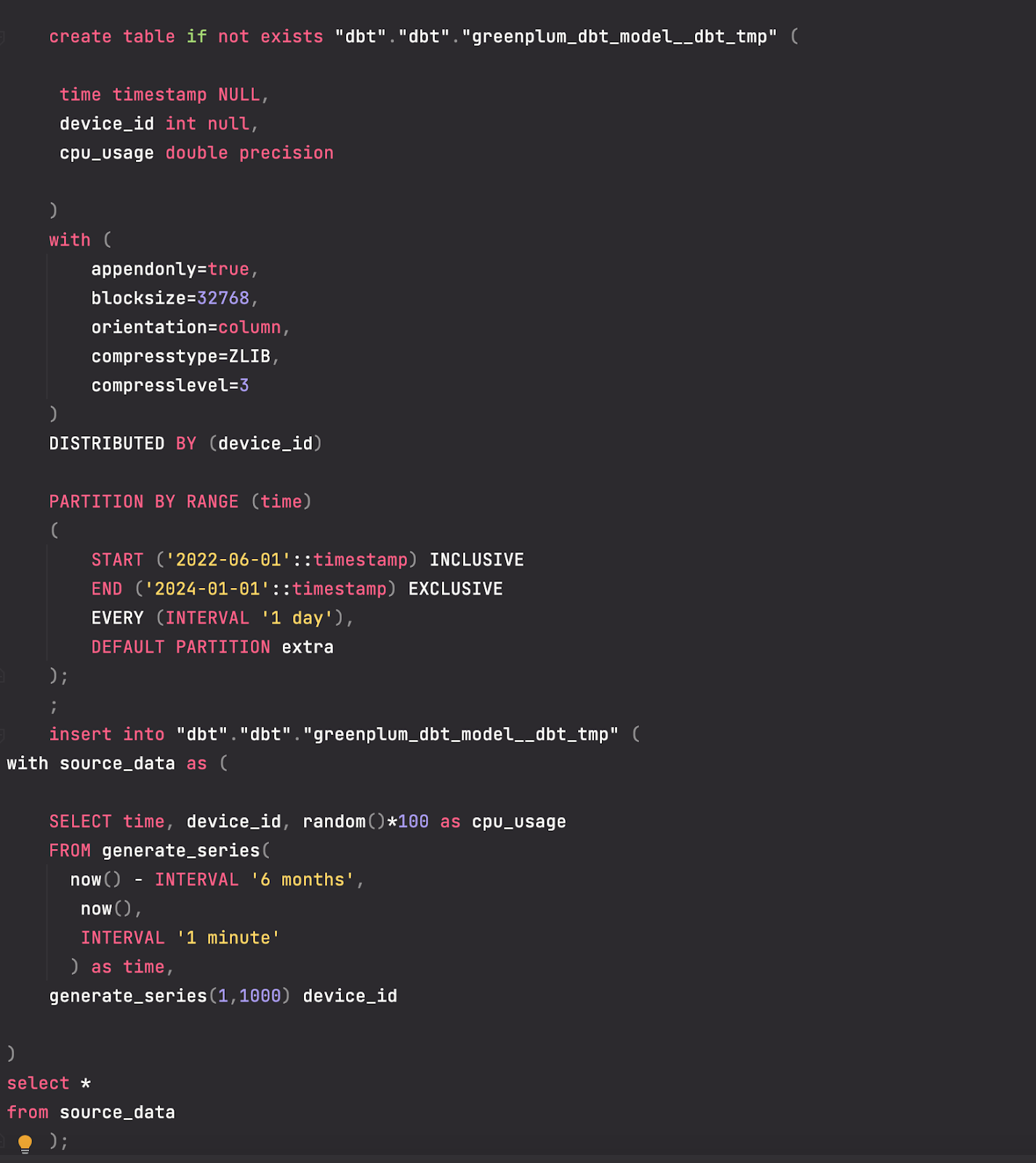
While for the second table, our data is distributed based on the device_id column. The table is column-oriented, partitioned daily with a ZLIB compression.
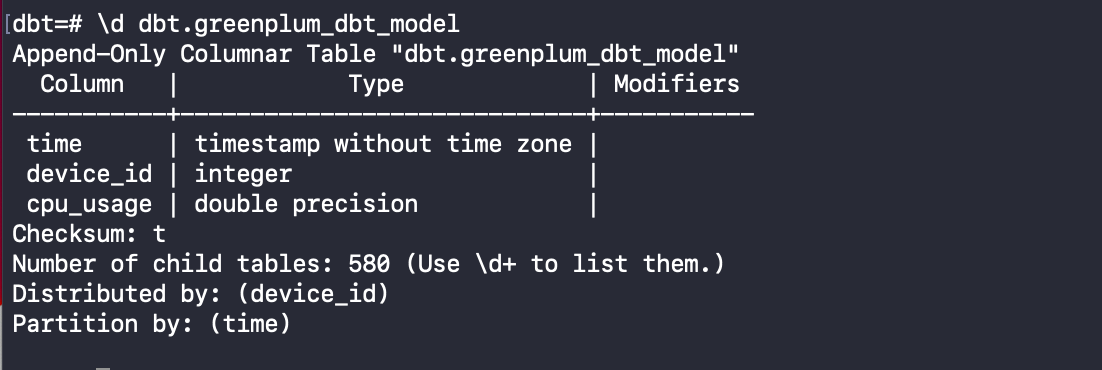
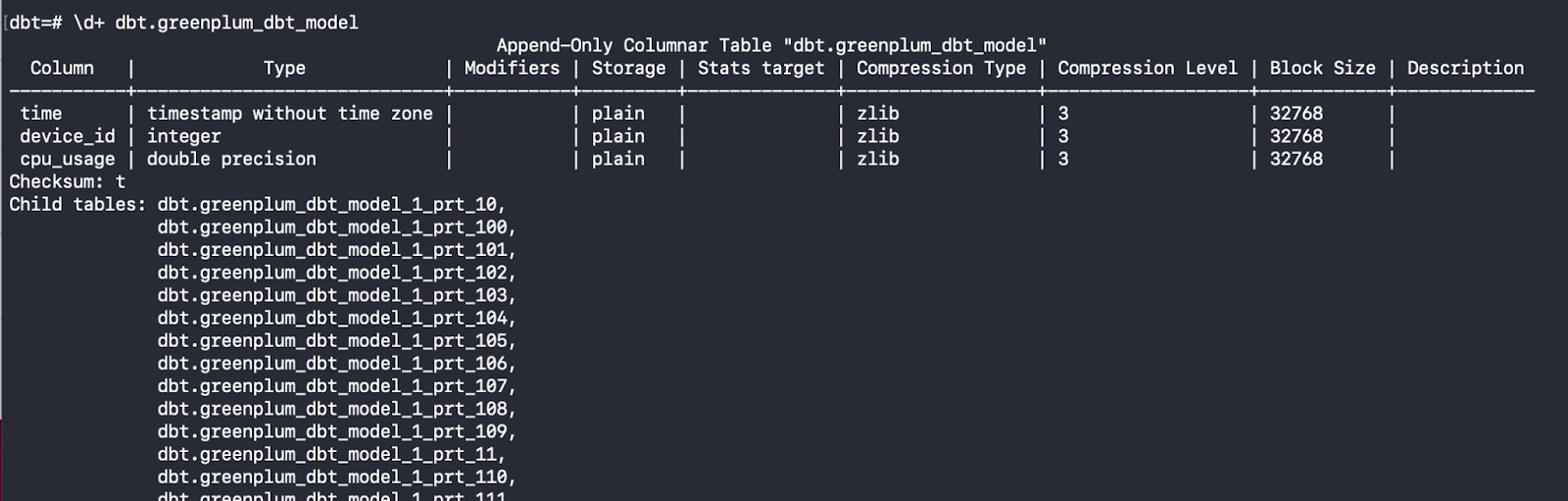
- When we return to the Greenplum console, we can select from these models:
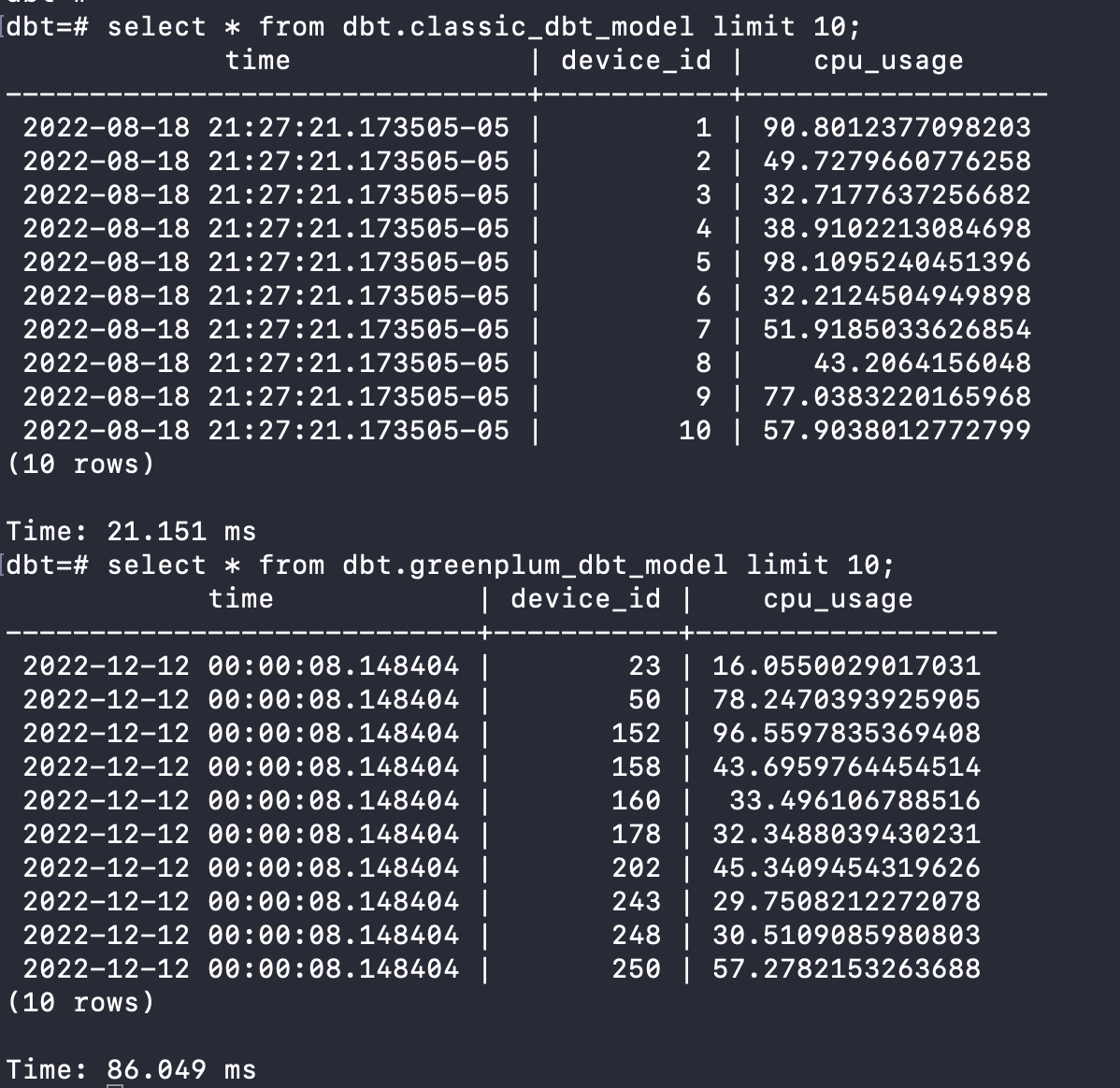
Query Performance & Results Analysis:
As you can see, tables in Greenplum have powerful optimisation configurations that should improve query performance. To compare query performance between our newly created dbt tables, we will run analytical queries against these two large tables of 265 million records.
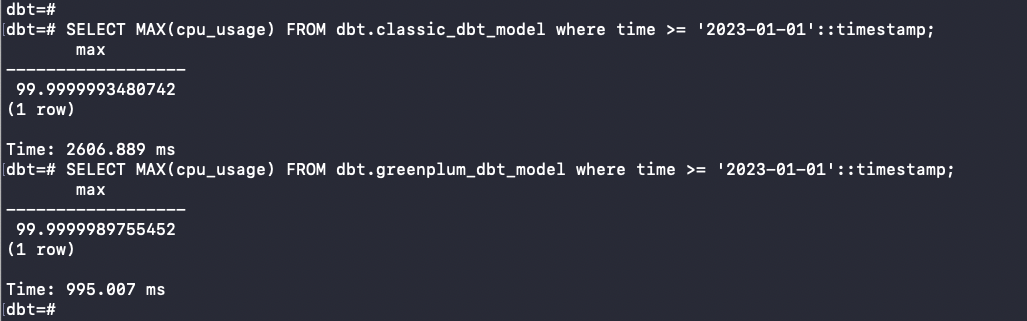
- **SELECT MAX(cpu_usage) FROM dbt. *_dbt_model where time >= ‘2023–01–01’::timestamp:
- SELECT COUNT() FROM dbt.*_dbt_model WHERE cpu_usage >= 99 AND (time between ‘2023–02–18’::timestamp and ‘2023–02–20’::timestamp):**
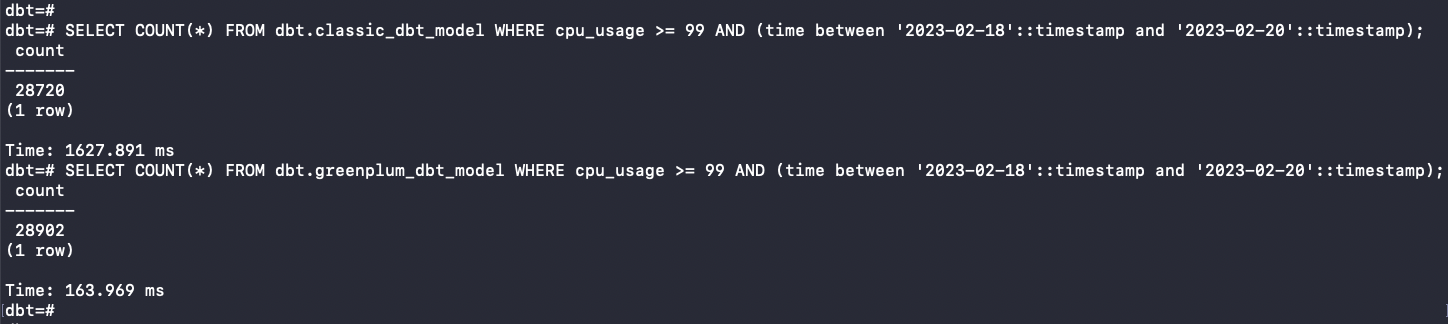
As expected, analytical queries are much faster on the greenplum_dbt_model table; our query took only 0.163 seconds to query a 265 million rows table thanks to the advanced Greenplum capabilities from distribution, partitioning and column orientation features, which is ten times faster than the ***classic_dbt_model ***table that took more than a second.
Conclusion:
The winning combination of Greenplum and dbt dramatically simplifies your overall data architecture by providing a centralised and familiar SQL-based environment for collaborative data transformation.
Built for performance on top of open source technologies with widespread community support — dbt and Greenplum — ensures ongoing innovation and eliminates the risk of any vendor lock-in.
Thanks for reading! Any comments or suggestions are welcome! Check out other Greenplum articles here.