Why VMware Greenplum as a Massive Vector Database for your Analytical needs ?

Introduction
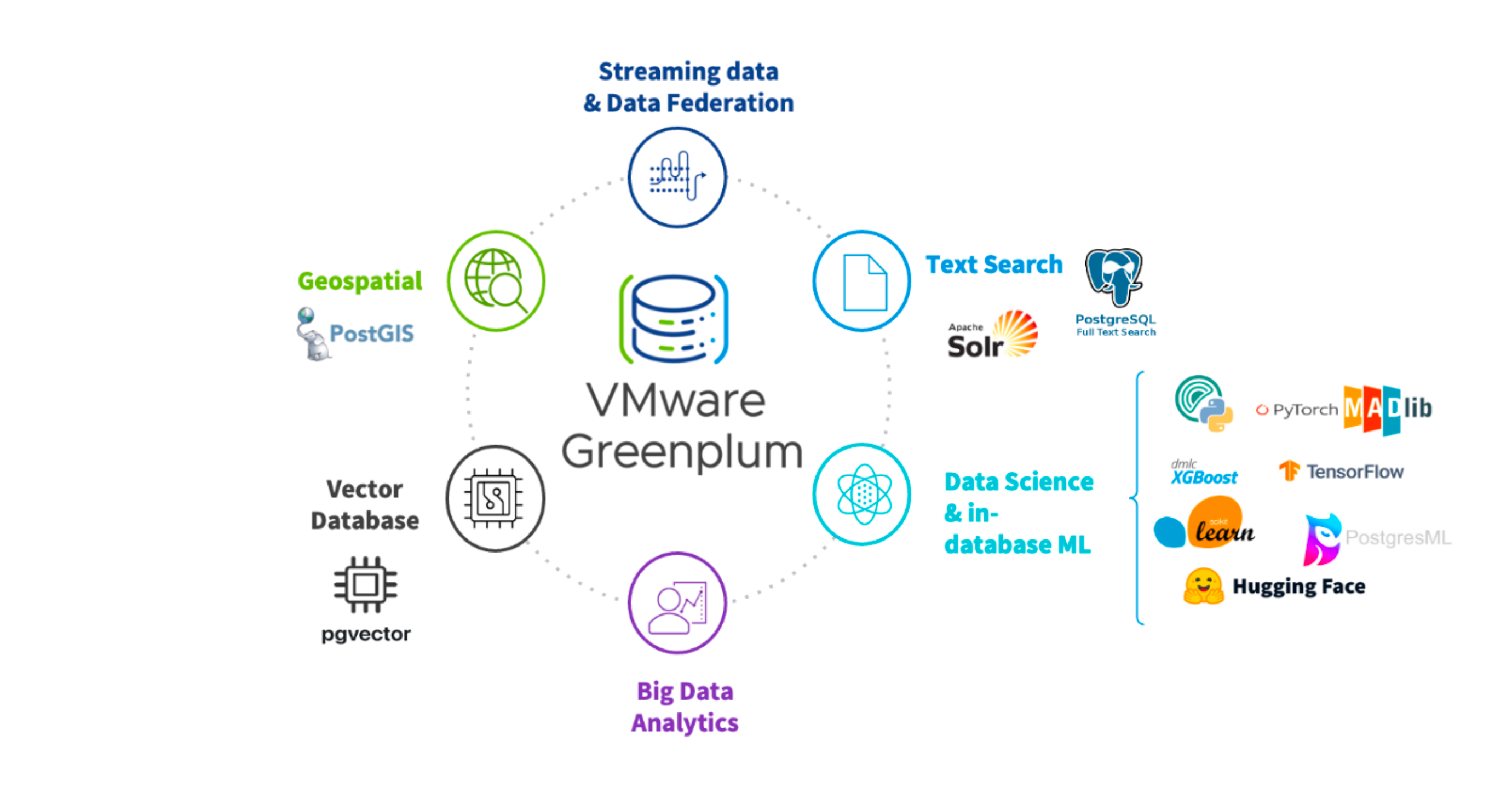
Greenplum 7, the upcoming release of the Greenplum data warehouse based on PostgreSQL v12, marking a huge milestone for the Greenplum community. This release will support many new extensions for AI/ML, such as pgvector and postgresML.
This advancement seamlessly complements Greenplum’s existing capabilities by facilitating support for unstructured data within the data warehouse through vector embeddings. It extends to data federation, enabling seamless querying (both read and write operations) across various databases and datalakes, streaming capabilities to ingest real-time data from Kafka and RabbitMQ, in addition to geospatial analytics through PostGIS and text analytics through Full-text search and GPText (built upon Apache SolR).
This expansive feature set is further enhanced by a wide array of in-database machine learning capabilities, which include support for Python, R, MADlib extension, and Containers. These capabilities enable the training, fine-tuning, and deployment of models within the Greenplum environment.
In this blog post, we will delve into the revolutionary impact of pgvector on Greenplum, exploring the new horizons it opens.
Furthermore, we will demonstrate why VMware Greenplum stands as a great choice for companies in search of a Modern Data Warehouse/Platform equipped with Vector Search capabilities tailored for analytical excellence.
pgvector — a PostgreSQL vector search extension
pgvector is an open-source vector database extension for PostgreSQL. It enables you to store vector embeddings and perform vector similarity search in PostgreSQL. It is particularly useful for applications involving natural language processing, such as those built on top of OpenAI’s GPT models.
pgvector extension brings great new capabilities to PostgreSQL, to become a Vector Database, it became a great choice for developers seeking to develop new AI-applications empowered with vector similarity search while keeping ACID compliance of an object-relational database like PostgreSQL.
The versatility and efficiency of vector databases make them valuable for a wide range of applications across various industries. Some of the prominent ones are:
- **Natural language processing (NLP): **Vector databases facilitate semantic search and text analysis through efficient handling of word embeddings or document vectors. They enable tasks like document classification, sentiment analysis, and keyword extraction, helping organizations make sense of massive volumes of textual data from sources like social media, forums, customer interactions — and currently most importantly — LLM prompt inputs.
- **Image search and recognition: **reverse image search, object detection, and facial recognition…
- Recommendation systems: for modern e-commerce and content platforms, analyze user preferences and content features to generate personalized and highly relevant recommendations to users in real-time.
VMware Greenplum + pgvector: a Massive Vector Database for Analytics
Thanks to the vector capabilities introduced by pgvector, Greenplum takes a giant leap forward, positioning itself as a unique data warehouse and a great vector database for analytical purposes.
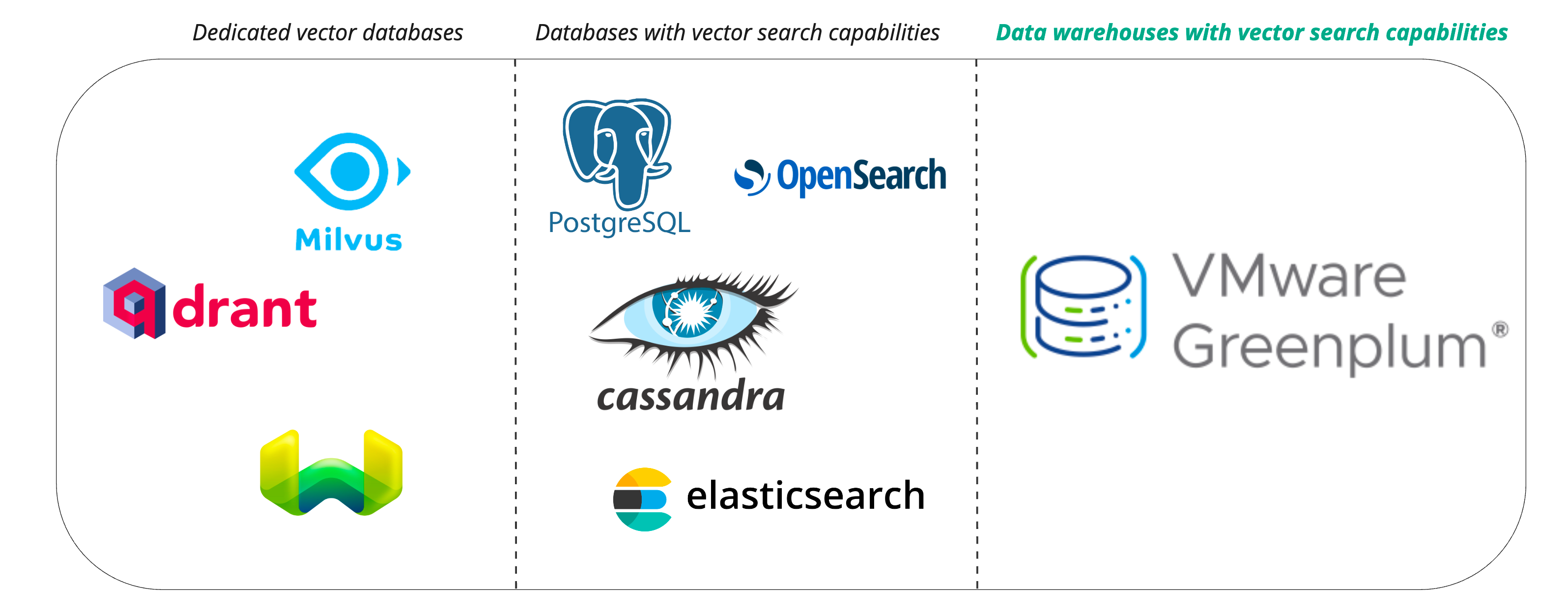
However, you may wonder, “Does Greenplum truly fulfill the criteria of a robust and proven vector database?”
Revisiting the fundamentals, vector databases possess the ability to store and retrieve vectors as multidimensional points.
They amplify their capabilities by enabling efficient and rapid lookup of nearest neighbors within the N-dimensional space. Typically driven by k-nearest neighbor (k-NN) indexes and bolstered by algorithms such as Hierarchical Navigable Small World (HNSW) and Inverted File Index (IVF), vector databases offer additional functionalities like data management, fault tolerance, access control, and an adept query engine.
From the description above, we can extract the requirements for an advanced vector database, which ideally encompasses:
- Vector-Store.
- Vector Similarity Search with Diverse Distance Metrics.
- Indexing.
- Speed.
- Reliability (Fault Tolerance and High Availability).
- Distributed Architecture.
- Scalability.
With this framework in mind, let’s delve into how Greenplum fulfills each of these requisites:
1. Vector-Store (Storing vectors and embeddings):
Before storing vectors inside Greenplum, you should enable the pgvector extension by running the following CREATE EXTENSION statement:
CREATE EXTENSION vector;
To create a table for storing vectors, use the following SQL command, adjusting the dimensions as needed.
CREATE TABLE vectors_table (
id BIGSERIAL PRIMARY KEY,
embedding VECTOR(3)
);
The command generates a table named vectors_table with an embedding column capable of storing vectors with 3 dimensions.
You can store vectors in your table, execute an INSERT statement similar to the following to store embeddings:
INSERT INTO vectors_table (embedding) VALUES ('[1,2,3]'), ('[4,5,6]');
This command inserts two new rows into the vectors_table table with the provided embeddings.
2. Vector Similarity Search with Diverse Distance Metrics:
To retrieve vectors and calculate similarity, use SELECT statements and the built-in vector operators.
For instance, you can find the most similar item to a given embedding using the following query:
SELECT * FROM vectors_table ORDER BY embedding <-> '[3,1,2]' LIMIT 1;
This query computes the Euclidean distance (L2 distance) between the given vector and the vectors stored in the vectors_table table, sorts the results by the calculated distance, and returns the top 5 most similar vectors.
- pgvector also supports inner product (<#>) and cosine distance (<=>).
3. Indexing:
Using an index on the vector column can improve query performance with a minor cost in recall.
You can add an index for each distance function you want to use. For example, the following query adds an index to the embedding column for the L2 distance function:
CREATE INDEX ON vectors_table USING ivfflat (embedding vector_l2_ops) WITH (lists = 100);
pgvector currently supports Inverted File Flat (ivfflat) indexing algorithm for approximate nearest neighbor search.
4. Speed:
The integration of pgvector fortifies Greenplum’s capacity for vector semantic searches.
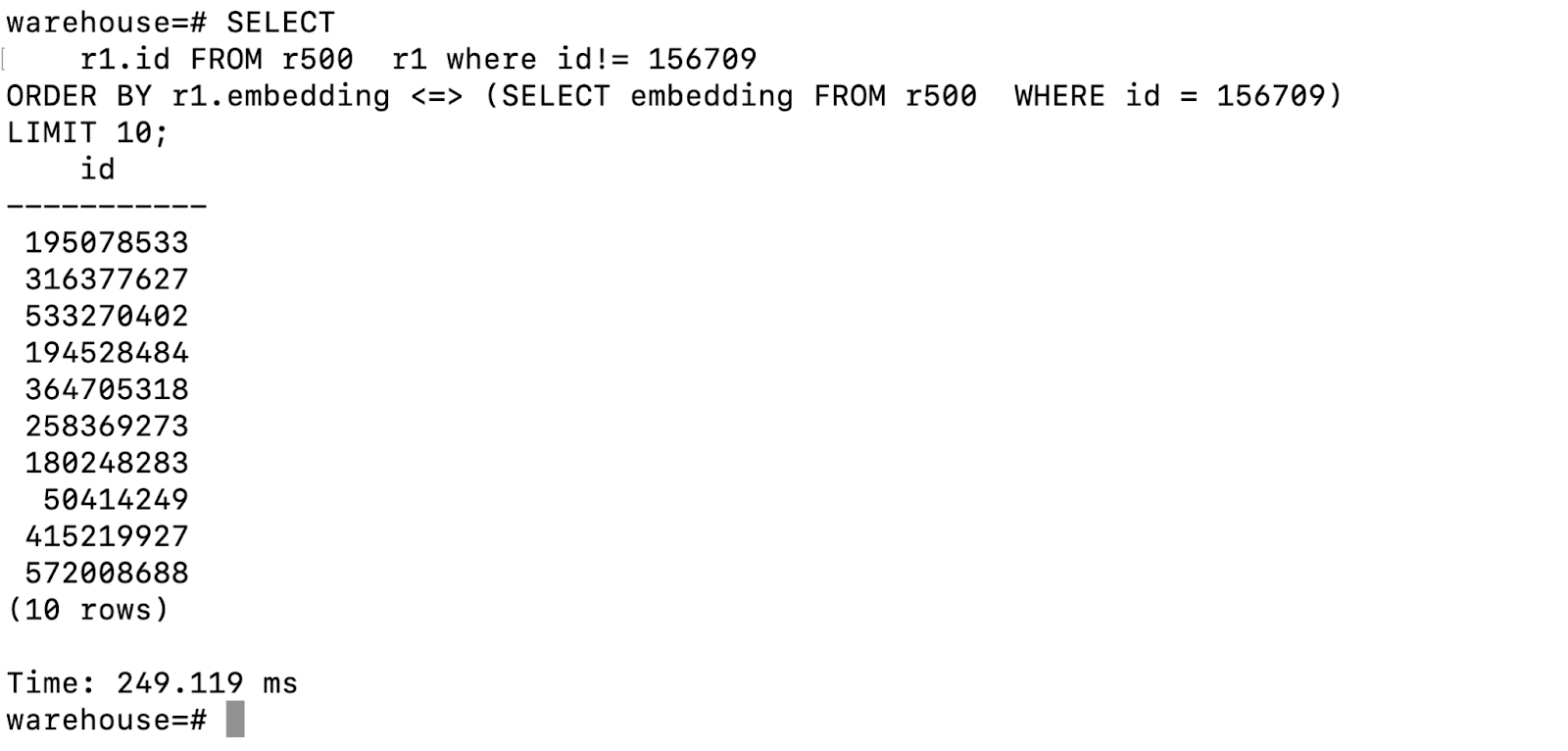
Rigorous performance testing conducted within our Greenplum lab cluster, involving three segment hosts on GCP compute engines of c2-standard-16c, yielded remarkable results.
Our cluster demonstrated less than 250 milliseconds for a Cosine search in Greenplum across a Vector Table containing 500 million rows, each vectors with 512 dimensions !
5. Reliability (Fault Tolerance and High Availability):
Greenplum data warehouse is a reliable distributed system, it has automated Fault Detection and Self-Healing.
- Failover and Load Balancing: Mirroring enables automatic failover mechanisms, where if a primary segment becomes inaccessible, traffic can be redirected to the mirrored segment. This load balancing ensures that queries and workloads continue to be processed even during failures.
- Improved Data Integrity: Mirroring enhances data integrity by providing a second copy of the data that can be used for validation and comparison. This helps identify and rectify discrepancies or errors that may occur in the primary copy. Even if one copy of the data is compromised, the mirrored copy remains intact.
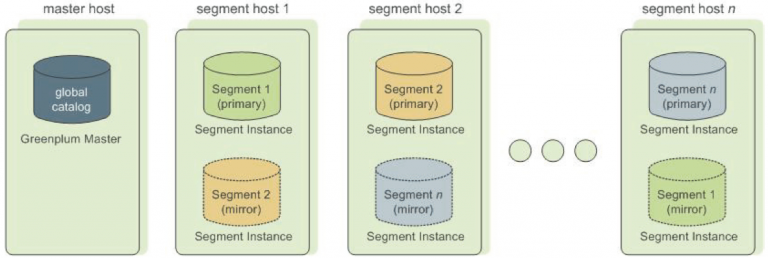
6. Distributed Architecture:
Greenplum’s Massively Parallel Processing (MPP) architecture divides data and tasks across multiple nodes, enabling parallel processing. This design enhances query performance and fault tolerance, as tasks can be distributed and executed simultaneously.
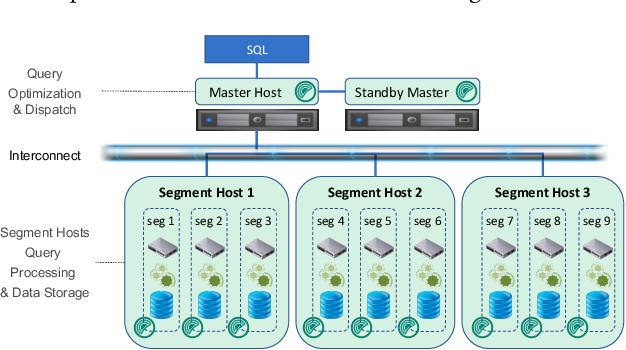
7. Scalability:
Greenplum’s elastic scalability allows for easy expansion by adding more nodes, accommodating growing data and user demands without compromising performance.
Conclusion:
Through these comprehensive demonstrations, we not only validated the technological capabilities of VMware Greenplum and the pgvector extension but also demonstrated why it stands as great choice for companies willing to augment their data platforms for new AI/ML workloads.
As a modern data warehouse and a massive vector database, Greenplum offers an unmatched suite of features encompassing vector storage, lightning-fast query performance, fault tolerance, high availability, scalability, and more.
In the ever-evolving landscape of data analytics, Greenplum data platform does not only meet but exceeds the demands of modern businesses seeking advanced analytical capabilities. Its integration with the pgvector extension propels it to the forefront of the industry, equipping organizations with the tools they need to extract meaningful insights from vast amounts of vector data.